池化层
本文基于d2l项目内容整理,介绍池化层的基本概念、工作原理和实现方法,包括最大池化和平均池化的原理与应用。
1. 池化层的作用与意义
像素矩阵输入到卷积层,与卷积核进行互相关运算后,由局部感受野提取局部特征(如边缘、纹理等),保留了输入数据的空间结构。但计算机视觉任务的决策基于图像全局,而不是局部特征。
池化层的核心作用:
池化层 (pooling layer) 在卷积神经网络中发挥了重要的作用,旨在促进网络更好地学习抽象特征:
- 降采样:对特征图进行下采样,减少其空间维度、降低模型复杂度,减小计算量和过拟合风险
- 特征抽象:提取特征中最显著的关键部分而去掉不必要的细节,使特征对微小的空间变动具有更好的不变性
- 扩大感受野:局部感受野的范围将随着层的叠加而逐渐扩展,使网络最终生成对全局敏感的表示
1.1 池化操作的基本类型
与卷积层的感受野类似,池化层使用池化窗口 (pooling window) 限制降采样过程中区域的大小和形状。
最大池化 (max-pooling)
将每个池化窗口的最大值作为新的特征图元素,能够:
- 保留最显著的特征
- 对小幅度的平移具有不变性
- 减少噪声影响
平均池化 (average-pooling)
将每个池化窗口的平均值作为新的特征图元素,能够:
- 保留整体信息
- 平滑特征表示
- 减少过拟合风险
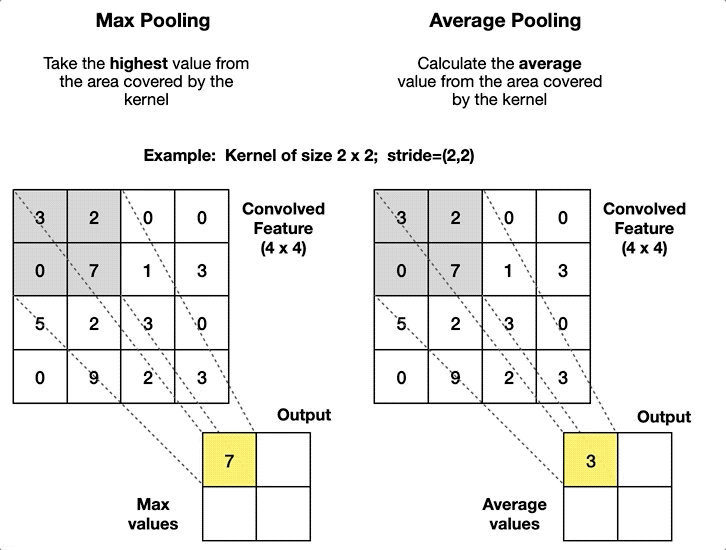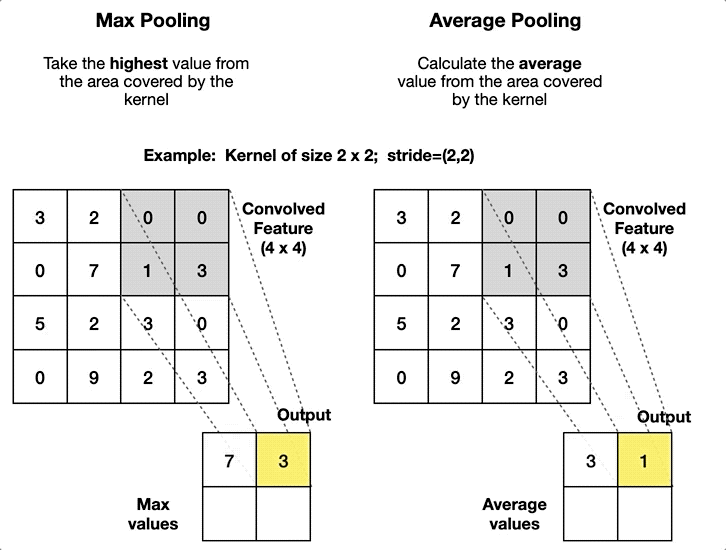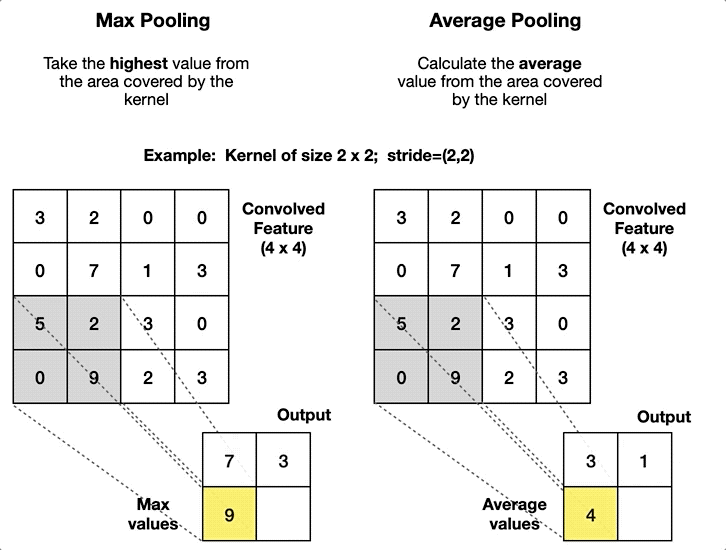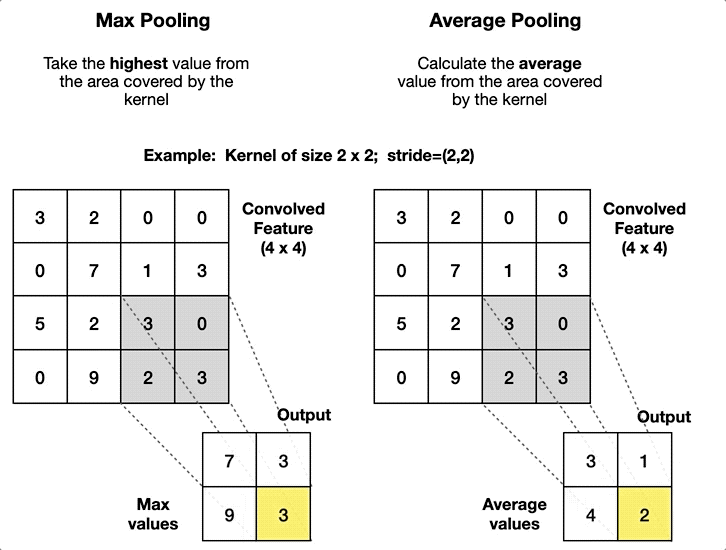
步长设计的差异:
- 池化层:默认步长等于池化核大小,保证了无重叠的下采样
- 卷积层:默认步长为 1,最大程度保留空间信息,有助于平滑过渡
2. 池化层的实现
与卷积层中执行二维互相关运算的函数类似,我们定义 pool2d() 函数实现基本的池化操作:
2.1 基础池化函数实现
1 | from typing import Literal, Tuple |
查看输出结果
1 | 输入数据: |
2.2 填充和步幅
与卷积层类似,池化运算前同样支持对特征图边界的填充 (padding),并通过步幅 (stride) 改变池化窗口移动的步长。
池化层的参数控制:
- kernel_size:池化窗口的大小
- stride:池化窗口移动的步幅
- padding:在输入周围添加的填充
以下使用 PyTorch 中内置的二维最大池化层 nn.MaxPool2d() 演示:
1 | import torch |
查看输出结果
1 | 原始数据: |
3. 多通道池化
与卷积层类似,池化层也需要处理多通道的数据。但与卷积层不同的是:
多通道处理的差异:
- 卷积层:对输入进行卷积运算后将各通道结果加和
- 池化层:为每个通道独立应用相同的池化窗口,保持通道数不变
3.1 多通道池化实现
1 | import torch |
查看输出结果
1 | 多通道输入数据: |
多通道池化的特点:
- 输入和输出的通道数保持一致
- 每个通道独立进行池化运算
- 不同通道之间没有信息交换
- 空间维度按照池化参数进行缩减
总结
本文介绍了池化层的核心概念和实现方法:
- 池化层的作用:降采样、特征抽象、扩大感受野,是CNN中重要的下采样组件
- 池化类型:最大池化保留显著特征,平均池化保留整体信息
- 参数控制:通过kernel_size、stride、padding等参数灵活控制池化操作
- 多通道处理:每个通道独立池化,保持通道数不变
池化层作为CNN的重要组成部分,与卷积层配合使用,能够有效减少计算量、提高模型的泛化能力,同时保持对关键特征的敏感性。
相关推荐

评论