残差块与分组残差块
本文基于d2l项目内容整理,介绍残差连接的核心思想,以及ResNet和ResNeXt中残差块和分组残差块的设计原理与实现方法。
传统神经网络的每一层直接学习从输入到输出的映射,使得网络的层层堆叠就是函数的相互嵌套,累积的依赖性和协同效应、信号在层中的衰减、局部最小值等,显著增大了模型训练的难度。
1. 残差块与分组残差块的结构
1.1 残差块
残差连接的核心思想:
残差块 (residual block) 是残差网络 (ResNet) 中的关键组件,用跳跃连接 (skip connection) 学习从输入到输出的差异,具有以下优势:
- 简化学习:学习残差比学习复杂映射简单
- 梯度传递:跳跃连接作为捷径使梯度更易于传递
- 缓解梯度问题:协同批量归一化层缓解梯度消失/爆炸问题
- 支持深层网络:能促进约 100 层以上的深层网络快速收敛
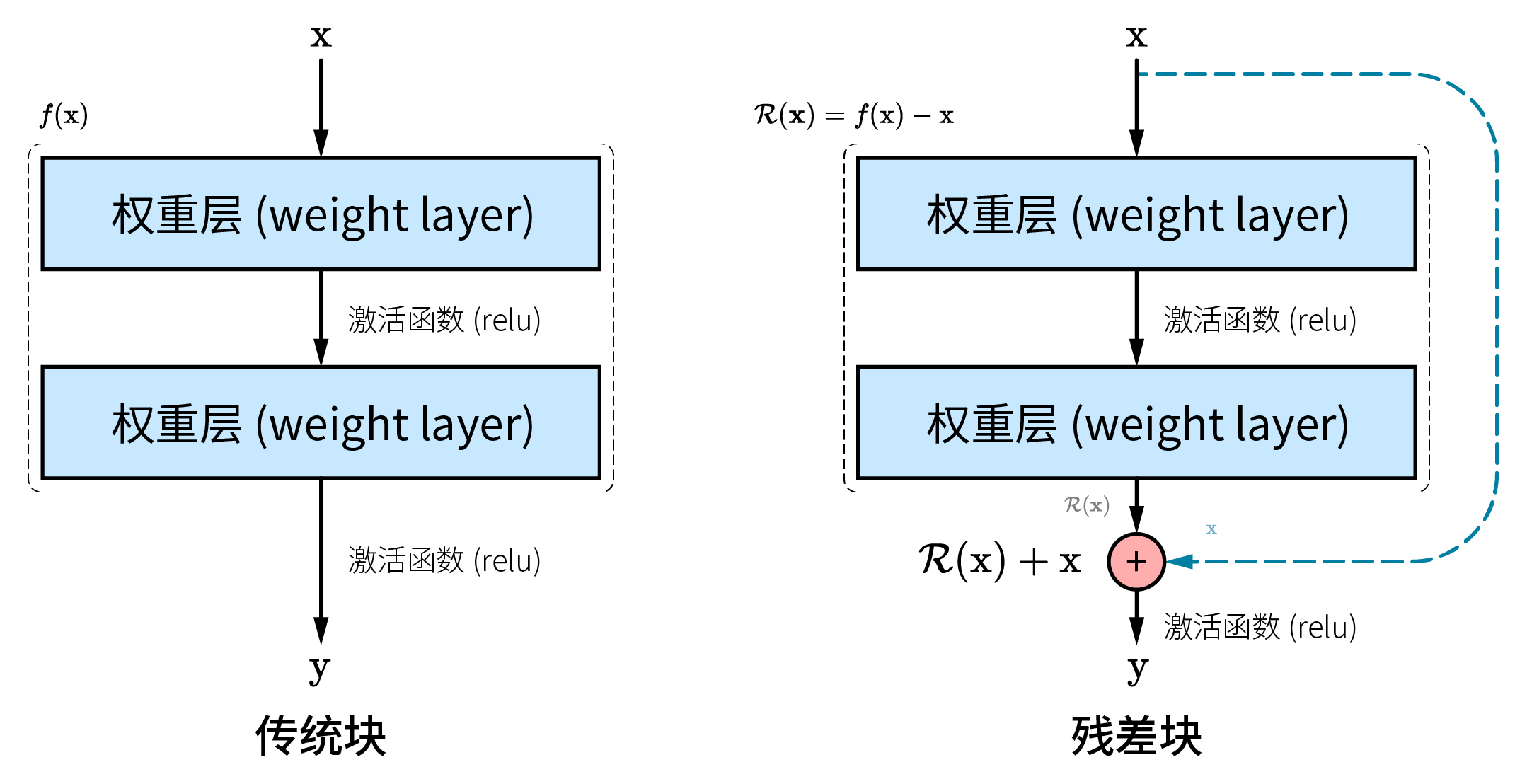
典型的残差块结构沿用 VGG 网络的卷积层参数,从步幅为 1、通道数与输入一致的 3×3 卷积层开始,经过批量归一化和 ReLU 函数激活后,到达第二个卷积层并再次批量归一化,得到被称为残差映射 的输出。然后,残差映射值与来自跳跃连接的原始输入
的输出。然后,残差映射值与来自跳跃连接的原始输入 相加,得到
相加,得到 。最终被 ReLU 函数激活输出。
。最终被 ReLU 函数激活输出。
ResNet 的后续版本 (ResNet v2) 调整了每个卷积块的内部顺序,由“卷积层 (Conv2d) → 批量归一化层 (BatchNorm) → 激活函数 (ReLU)”改为“批量归一化层 (BatchNorm) → 激活函数 (ReLU) → 卷积层 (Conv2d)”,称为卷积块的预激活 (pre-activate) 架构。
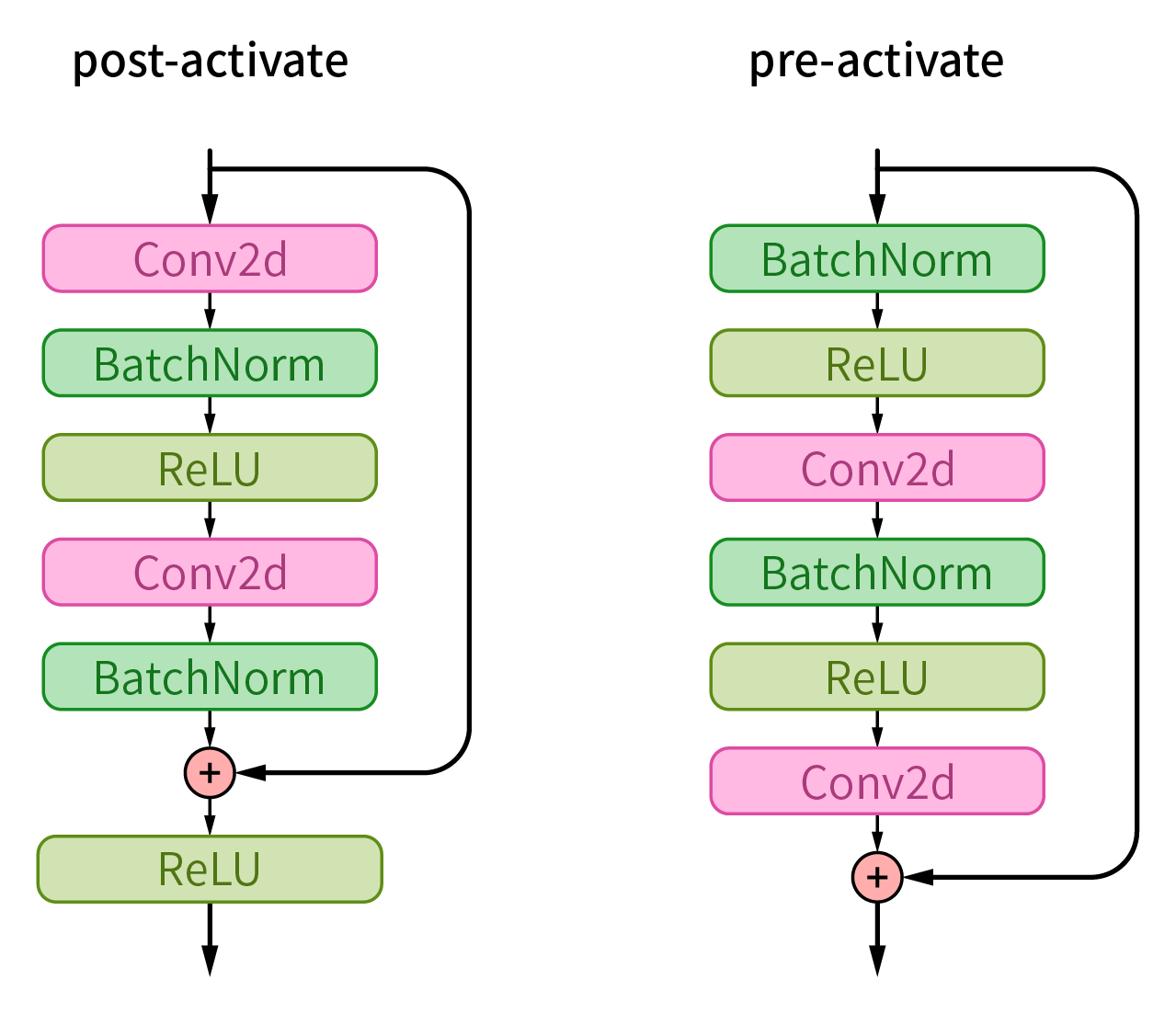
在后激活架构中,卷积层后的 BatchNorm 层与 ReLU 函数分别改变数据的分布特征并非线性化。而预激活架构的数据经批量归一化并激活后,才能作为卷积层的输入,使原始输出信号”纯净”而不发生”变形”(减少了额外的扰动)。有助于模型最大限度地维持特征的原始分布,并通过跳跃连接使原始输入和真实”增量 (residual)”相加,实现恒等映射。这种先统一数据分布,再由卷积层学习特征的方式促进了模型的快速收敛,使反向传播中的梯度更易于流动,进一步支持了深层网络的训练。
1.2 分组残差块
传统 CNN 主要通过增加深度(层数)提升模型的表达能力,通过增加宽度(通道数)促进信息的传递。残差块缓解了更深的模型难以训练的问题,但没有考虑因通道数的增加而导致的计算成本增长——卷积核尺寸为 ,输入通道数为
,输入通道数为 、输出通道数为
、输出通道数为 时的计算复杂度为
时的计算复杂度为 。
。
ResNeXt 的创新点:
受 GoogLeNet 中 Inception 块的启发,ResNeXt 作为 ResNet 的进一步改进,引入了分组残差块:
- 分组设计:将通道按基数 (cardinality) 分为独立学习的小组
- 多路径并行:避免所有通道间的冗余连接
- 多样化特征:在同样参数量下提供更丰富的特征表示
- 性能优势:实践证明,增加基数比增加宽度能带来更大收益
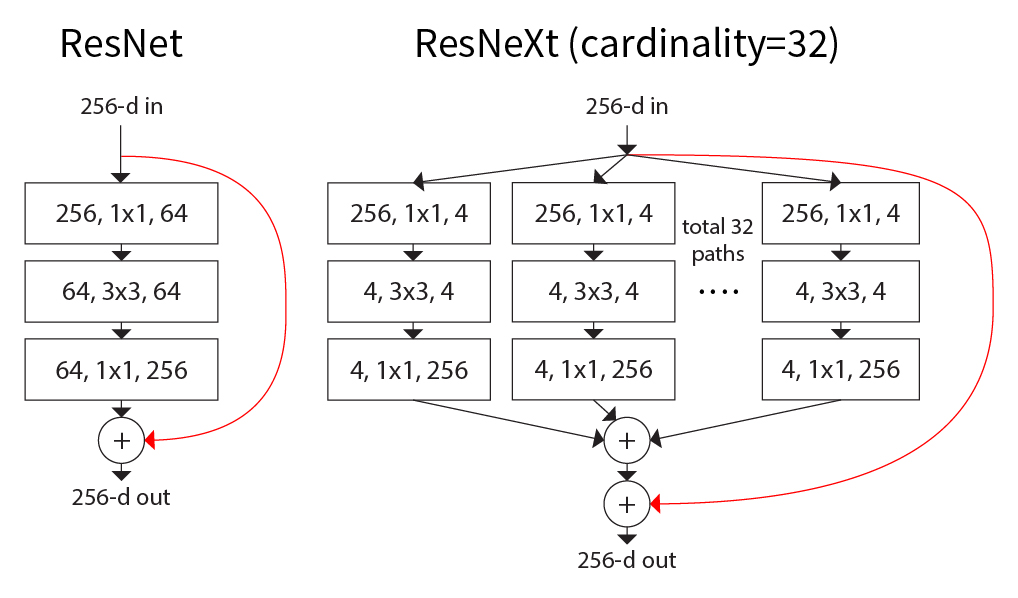
ResNeXt 使用分组卷积 (grouped convolution) 将个输入通道并行地分为 组,每组由
组,每组由 个通道组成。这些组独立地进行特征提取,分别产生
个通道组成。这些组独立地进行特征提取,分别产生 个通道的输出。最后连接为个通道。这样,计算复杂度和参数数量都减少了倍,为
个通道的输出。最后连接为个通道。这样,计算复杂度和参数数量都减少了倍,为 。
。
ResNeXt 引入的分组卷积思想对后来的轻量级网络设计(如 MobileNet、ShuffleNet)产生了重要影响,成为减少网络参数和计算量的重要技术。
2. 思路与代码实现
2.1 残差块
残差块(后激活)的实现思路如下:
- 使用 PyTorch,通过继承
nn.Module实现ResNetBlock残差块,并重载__init__()方法自定义模块结构、重载forward()方法自定义数据的流向; - 提供
in_channels和out_channels分别作为残差块的输入输出通道数。为了适应可能较深的网络,提供参数stride用于对空间尺寸的下采样。提供参数bottleneck_ratio以支持瓶颈 (bottleneck) 结构:减少中间层的通道数以减少计算量,并在输出前恢复维度,同时不牺牲模型的表达力。在进行残差连接中的维度匹配时,提供可选的downsample参数用于灵活地自定义下采样模块,而不是仅限于使用 1×1 卷积; 残差块的数据只有主路径
main_path和跳跃连接shortcut两个流向:标准残差块的主路径用于特征提取:由两个 3×3 卷积层堆叠,在第一个卷积层中执行下采样,最后一个卷积层不使用激活函数。当使用瓶颈结构时,中间层的输出数据通道数变为原始的 ¼(默认),然后在标准残差块主路径中恢复通道数;
跳跃连接用于将输入直接传递到输出,学习恒等映射:为了避免形状不匹配,当空间尺寸被
stride下采样或输入输出通道数不一致时,使用 1×1 卷积层调整输入数据的维度;每个卷积层的输出都被批量归一化,因此不必在卷积层中处理偏置项(
bias=False),避免冗余计算;- 向前传播时,分别计算来自主路径和跳跃连接的输出,并逐元素相加。最后激活求和结果;
- 以 ReLU 函数作为激活函数。
2.1.1 代码实现
1 | from typing import Optional |
2.1.2 模型测试
使用torchinfo库的summary函数执行更便利的输出维度测试。
不使用瓶颈结构:
from torchinfo import summary
model = ResNetBlock(128, 32, bottleneck_ratio=1)
summary(model, input_size=(4, 128, 64, 64))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNetBlock [4, 32, 64, 64] --
├─Sequential: 1-1 [4, 32, 64, 64] --
│ └─Conv2d: 2-1 [4, 32, 64, 64] 36,864
│ └─BatchNorm2d: 2-2 [4, 32, 64, 64] 64
│ └─ReLU: 2-3 [4, 32, 64, 64] --
│ └─Conv2d: 2-4 [4, 32, 64, 64] 9,216
│ └─BatchNorm2d: 2-5 [4, 32, 64, 64] 64
├─Conv2d: 1-2 [4, 32, 64, 64] 4,096
==========================================================================================
Total params: 50,304
Trainable params: 50,304
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 822.08
==========================================================================================
Input size (MB): 8.39
Forward/backward pass size (MB): 20.97
Params size (MB): 0.20
Estimated Total Size (MB): 29.56
==========================================================================================仅使用瓶颈结构:
from torchinfo import summary
model = ResNetBlock(128, 32, bottleneck_ratio=4)
summary(model, input_size=(4, 128, 64, 64))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNetBlock [4, 32, 64, 64] --
├─Sequential: 1-1 [4, 32, 64, 64] --
│ └─Conv2d: 2-1 [4, 8, 64, 64] 1,024
│ └─BatchNorm2d: 2-2 [4, 8, 64, 64] 16
│ └─ReLU: 2-3 [4, 8, 64, 64] --
│ └─Conv2d: 2-4 [4, 8, 64, 64] 576
│ └─BatchNorm2d: 2-5 [4, 8, 64, 64] 16
│ └─ReLU: 2-6 [4, 8, 64, 64] --
│ └─Conv2d: 2-7 [4, 32, 64, 64] 256
│ └─BatchNorm2d: 2-8 [4, 32, 64, 64] 64
├─Conv2d: 1-2 [4, 32, 64, 64] 4,096
==========================================================================================
Total params: 6,048
Trainable params: 6,048
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 97.52
==========================================================================================
Input size (MB): 8.39
Forward/backward pass size (MB): 16.78
Params size (MB): 0.02
Estimated Total Size (MB): 25.19
==========================================================================================既使用下采样又使用瓶颈结构:
from torchinfo import summary
model = ResNetBlock(128, 32, stride=3, bottleneck_ratio=4)
summary(model, input_size=(4, 128, 64, 64))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNetBlock [4, 32, 22, 22] --
├─Sequential: 1-1 [4, 32, 22, 22] --
│ └─Conv2d: 2-1 [4, 8, 64, 64] 1,024
│ └─BatchNorm2d: 2-2 [4, 8, 64, 64] 16
│ └─ReLU: 2-3 [4, 8, 64, 64] --
│ └─Conv2d: 2-4 [4, 8, 22, 22] 576
│ └─BatchNorm2d: 2-5 [4, 8, 22, 22] 16
│ └─ReLU: 2-6 [4, 8, 22, 22] --
│ └─Conv2d: 2-7 [4, 32, 22, 22] 256
│ └─BatchNorm2d: 2-8 [4, 32, 22, 22] 64
├─Conv2d: 1-2 [4, 32, 22, 22] 4,096
==========================================================================================
Total params: 6,048
Trainable params: 6,048
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 26.32
==========================================================================================
Input size (MB): 8.39
Forward/backward pass size (MB): 3.83
Params size (MB): 0.02
Estimated Total Size (MB): 12.24
==========================================================================================2.2 分组残差块
分组残差块ResNeXtBlock(预激活)的实现思路与残差块类似。主要区别在于:
- 使用预激活的卷积块;
- 为
torch.nn.Conv2d层引入groups参数,实现分组卷积。当groups为默认值 1 时,执行标准卷积;当groups大于 1 时,数据基于通道被分为多个独立的组单独执行卷积操作。这在保持模型表达能力不变的条件下,显著减少了计算量和参数数量; - 由于使用的是预激活的卷积块架构,需移除跳跃连接中的批量归一化层;
- 使用
bottleneck_ratio参数,支持对瓶颈结构中间层的通道缩减比例提供更灵活的控制,使用可选的downsample参数支持自定义下采样模块,而不是仅限于使用 1×1 卷积。
2.2.1 代码实现
1 | class ResNeXtBlock(nn.Module): |
2.2.2 模型测试
使用torchinfo库的summary函数执行更便利的输出维度测试。
不使用瓶颈结构:
from torchinfo import summary
model = ResNeXtBlock(128, 32, bottleneck_ratio=1)
summary(model, input_size=(4, 128, 64, 64))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNeXtBlock [4, 32, 64, 64] --
├─Sequential: 1-1 [4, 32, 64, 64] --
│ └─BatchNorm2d: 2-1 [4, 128, 64, 64] 256
│ └─ReLU: 2-2 [4, 128, 64, 64] --
│ └─Conv2d: 2-3 [4, 32, 64, 64] 36,864
│ └─BatchNorm2d: 2-4 [4, 32, 64, 64] 64
│ └─ReLU: 2-5 [4, 32, 64, 64] --
│ └─Conv2d: 2-6 [4, 32, 64, 64] 9,216
├─Conv2d: 1-2 [4, 32, 64, 64] 4,096
==========================================================================================
Total params: 50,496
Trainable params: 50,496
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 822.08
==========================================================================================
Input size (MB): 8.39
Forward/backward pass size (MB): 33.55
Params size (MB): 0.20
Estimated Total Size (MB): 42.15
==========================================================================================使用瓶颈结构与分组卷积:
from torchinfo import summary
model = ResNeXtBlock(128, 32, groups=4, bottleneck_ratio=4)
summary(model, input_size=(4, 128, 64, 64))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNeXtBlock [4, 32, 64, 64] --
├─Sequential: 1-1 [4, 32, 64, 64] --
│ └─BatchNorm2d: 2-1 [4, 128, 64, 64] 256
│ └─ReLU: 2-2 [4, 128, 64, 64] --
│ └─Conv2d: 2-3 [4, 8, 64, 64] 1,024
│ └─BatchNorm2d: 2-4 [4, 8, 64, 64] 16
│ └─ReLU: 2-5 [4, 8, 64, 64] --
│ └─Conv2d: 2-6 [4, 8, 64, 64] 144
│ └─BatchNorm2d: 2-7 [4, 8, 64, 64] 16
│ └─ReLU: 2-8 [4, 8, 64, 64] --
│ └─Conv2d: 2-9 [4, 32, 64, 64] 256
├─Conv2d: 1-2 [4, 32, 64, 64] 4,096
==========================================================================================
Total params: 5,808
Trainable params: 5,808
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 90.44
==========================================================================================
Input size (MB): 8.39
Forward/backward pass size (MB): 29.36
Params size (MB): 0.02
Estimated Total Size (MB): 37.77
==========================================================================================既使用下采样又使用瓶颈结构与分组卷积:
from torchinfo import summary
model = ResNeXtBlock(128, 32, stride=3, groups=4, bottleneck_ratio=4)
summary(model, input_size=(4, 128, 64, 64))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNeXtBlock [4, 32, 22, 22] --
├─Sequential: 1-1 [4, 32, 22, 22] --
│ └─BatchNorm2d: 2-1 [4, 128, 64, 64] 256
│ └─ReLU: 2-2 [4, 128, 64, 64] --
│ └─Conv2d: 2-3 [4, 8, 64, 64] 1,024
│ └─BatchNorm2d: 2-4 [4, 8, 64, 64] 16
│ └─ReLU: 2-5 [4, 8, 64, 64] --
│ └─Conv2d: 2-6 [4, 8, 22, 22] 144
│ └─BatchNorm2d: 2-7 [4, 8, 22, 22] 16
│ └─ReLU: 2-8 [4, 8, 22, 22] --
│ └─Conv2d: 2-9 [4, 32, 22, 22] 256
├─Conv2d: 1-2 [4, 32, 22, 22] 4,096
==========================================================================================
Total params: 5,808
Trainable params: 5,808
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 25.48
==========================================================================================
Input size (MB): 8.39
Forward/backward pass size (MB): 20.11
Params size (MB): 0.02
Estimated Total Size (MB): 28.53
==========================================================================================总结
本文介绍了残差连接的核心概念和两种主要实现方式:
🔗 残差块 (ResNet)
- 跳跃连接:通过残差学习简化深层网络训练
- 梯度流动:缓解梯度消失问题,支持 100+ 层网络
- 架构演进:从后激活到预激活架构的优化
🌐 分组残差块 (ResNeXt)
- 分组卷积:将通道分组,减少计算复杂度
- 基数概念:多路径并行提供多样化特征表示
- 效率提升:在保持性能的同时降低参数量和计算量
💡 技术影响
- 深层网络训练:残差连接成为深度网络的标准组件
- 轻量化网络:分组卷积思想影响了 MobileNet、ShuffleNet 等轻量级网络设计
- 架构创新:为现代深度学习网络架构奠定了重要基础
