CNN 网络架构的设计
本文基于d2l项目内容整理,深入探讨CNN网络架构设计的演进历程,从手工设计的网络工程方法到自动化的网络架构搜索技术,重点介绍RegNet的网络设计空间优化方法。
CNN架构设计的演进历程:
深度神经网络的架构设计历经了从直觉驱动到系统化设计的重要转变:
AlexNet:堆叠卷积块构建深度网络的开创性工作
VGG:证明3×3小卷积核的有效性
NiN:引入1×1卷积和全局平均池化的创新设计
GoogLeNet:Inception模块实现多尺度特征并行捕获
ResNet/ResNeXt:残差连接解决深度网络训练难题
网络架构搜索(NAS)的挑战:
NAS技术通过自动化搜索在给定设计空间内找到最优网络架构,涉及:
- 网络深度、宽度的组合优化
- 卷积核大小与数量的选择
- 层连接方式和激活函数配置
- 瓶颈比率和分组卷积参数
但NAS需要消耗巨大的计算资源,限制了其实际应用。
网络设计空间(NDS)的创新:
Radosavovic等人于2020年提出的NDS方法提供了更高效的解决方案:
- 结合手动设计洞察与NAS系统性优势
- 通过分析参数组合找出通用设计原则
- 优化整个网络族而非单一网络实例
- 产出RegNetX/RegNetY系列高性能网络
1. AnyNet:系统化的网络设计空间
1.1 网络架构组成
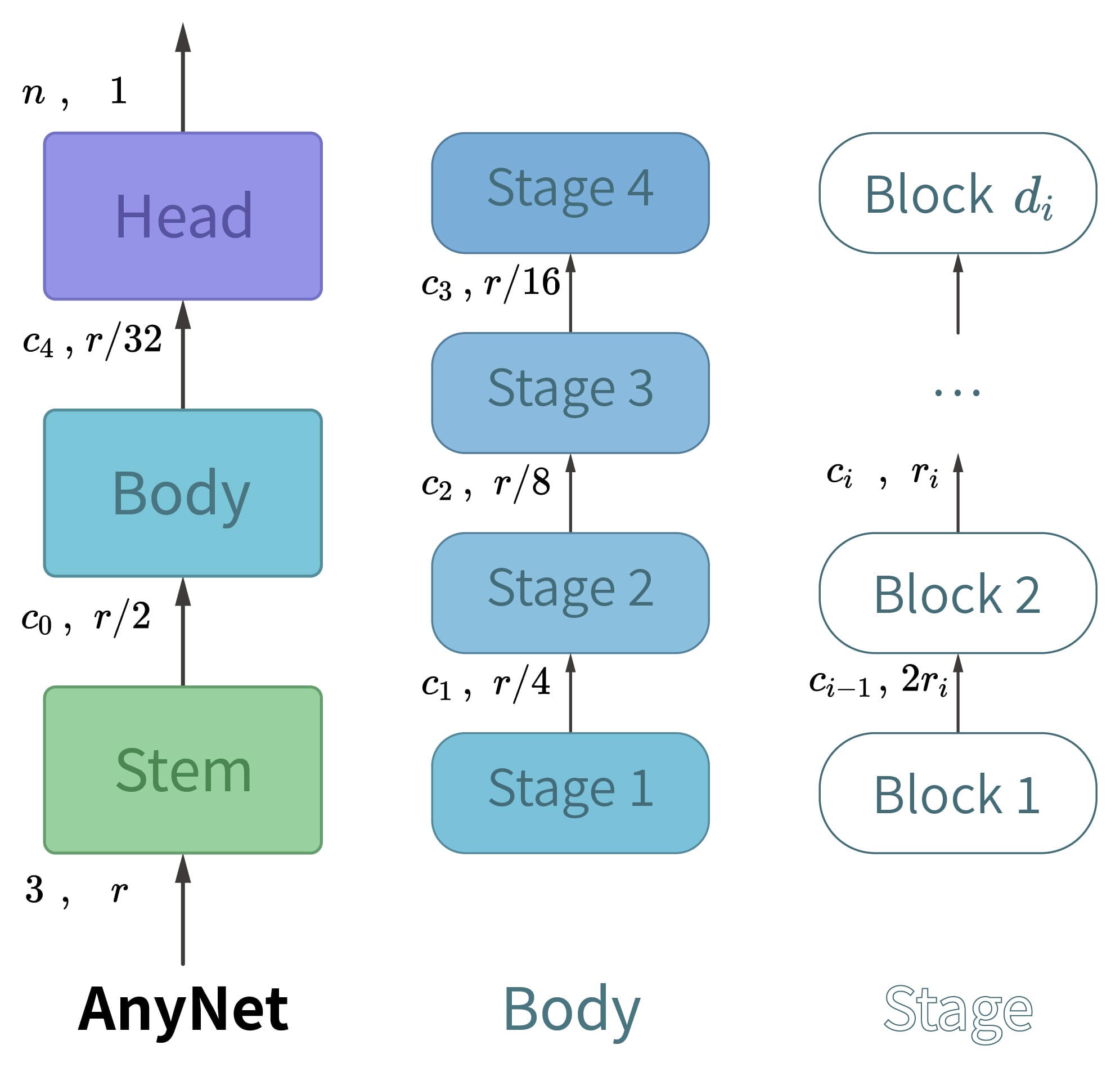
AnyNet网络架构的三层结构:
AnyNet探索了计算机视觉网络的统一设计框架,由三个核心组件构成:
茎 (Stem):快速降维的初始处理层
主体 (Body):多阶段的特征提取核心
头 (Head):任务特定的输出映射层
茎 (Stem) 的功能与设计:
主要功能:
- 接收RGB图像输入 (3×224×224)
- 快速降低空间维度 (224×224 → 112×112)
- 增加特征通道数 (3 → $w_0$ 通道)
- 为后续特征提取做准备
设计细节:
- 使用步幅为2的3×3卷积层实现下采样
- 包含批量归一化层提高训练稳定性
- 遵循深度CNN早期快速降维的标准实践
主体 (Body) 的多阶段设计:
4阶段渐进式处理:
各阶段的分辨率与通道变化:
- 阶段1:$w_0 \times 112^2 \rightarrow w_1 \times 56^2$
- 阶段2:$w_1 \times 56^2 \rightarrow w_2 \times 28^2$
- 阶段3:$w_2 \times 28^2 \rightarrow w_3 \times 14^2$
- 阶段4:$w_3 \times 14^2 \rightarrow w_4 \times 7^2$
设计原则:
- 每阶段空间分辨率减半 (面积减为1/4)
- 逐步增加特征通道数
- 使用ResNeXt块作为基本构建单元
- 第一个块负责维度变换,后续块进行特征精炼
头 (Head) 的标准化设计:
分类头的处理流程:
- 全局平均池化:$w_4 \times 7^2 \rightarrow w_4 \times 1^2$
- 特征扁平化:$w_4 \times 1^2 \rightarrow w_4$
- 全连接映射:$w_4 \rightarrow n_c$ (分类数)
适应性设计:
- 可根据具体任务调整 (分类、检测、分割)
- 标准化的接口便于模块化设计
- 支持不同的输出维度需求
1.2 ResNeXt块的参数化设计
ResNeXt块的关键参数:
AnyNet使用ResNeXt块作为基本构建单元,涉及两个核心参数:
瓶颈比率 $b$:控制中间3×3卷积层的通道压缩比例
分组卷积组数 $g$:决定分组卷积的并行度和参数效率
瓶颈比率 $b$ 的作用机制:
当输出通道数为 $w$ 时,中间通道数为 $\lfloor w/b \rfloor$:
通道压缩策略:
- $b = 1$:无压缩,中间通道数 = 输出通道数
- $b = 2$:压缩一半,中间通道数 = 输出通道数/2
- $b = 4$:压缩到1/4,中间通道数 = 输出通道数/4
实验发现:$b = 1$ (无压缩) 时模型表现最佳
分组卷积组数 $g$ 的权衡:
参数与性能的权衡:
优势:
- 更大的 $g$ 值减少参数量和计算量
- 提高模型的参数效率
- 增强特征的多样性
劣势:
- 可能限制网络的表达能力
- 过度分组导致特征交互不足
AnyNet的超参数空间:
4×4+1 = 17个超参数:
对于4个阶段,每个阶段包含4个参数:
- 瓶颈比率 $b_i$ (4个)
- 分组卷积组数 $g_i$ (4个)
- 输出通道数 $w_i$ (4个)
- 阶段深度 $d_i$ (4个)
- 茎输出通道数 $w_0$ (1个)
搜索复杂度:当每个参数有 $k$ 种选择时,搜索空间为 $k^{17}$
1.3 AnyNet代码实现
模块化设计理念:
AnyNet采用高度模块化的设计,通过配置参数灵活构建不同规模的网络架构。实现中从ResNet.py导入ResNeXtBlock作为基本构建单元。
1 | from dataclasses import dataclass |
查看AnyNet模型结构分析
1 | if __name__ == "__main__": |
1 | =============================================================================================== |
2. 网络设计空间的分布和参数分析
2.1 设计空间复杂度问题
搜索空间爆炸问题:
AnyNet的17个超参数带来了巨大的搜索挑战:
- 4个阶段 × 4类参数 + 1个茎参数 = 17个超参数
- 当每个参数有 $k$ 种选择时,搜索空间达到 $k^{17}$
- NAS方法即使找到最优单一网络,也难以获得通用设计洞察
- 设计空间变化时需要重新进行昂贵的搜索过程
2.2 NDS方法的核心假设
网络设计空间方法的四个关键假设:
NDS方法基于以下理论假设来简化复杂的架构搜索问题:
普遍设计原则:存在通用的设计原则能使大多数网络获得良好性能
早期评估有效性:早期训练结果能可靠评估网络性能,无需完全收敛
规模迁移性:小型网络的设计洞察可迁移到大型网络
参数独立性:网络参数间交互效应较小,可独立优化
2.3 累积分布函数(CDF)分析
CDF评估方法:
NDS方法使用累积分布函数来评估设计空间的质量:
其中 $e$ 为错误率阈值,$F(e)$ 表示网络错误率不超过阈值的概率。
CDF的数学表示:
从设计空间分布 $\mathcal{D}$ 中采样 $n$ 个网络,错误率为 $e_1, e_2, \ldots, e_n$:
其中 $\mathbb{I}(\cdot)$ 为指示函数:
- 当 $e_i \leq e$ 时,$\mathbb{I}(e_i \leq e) = 1$
- 当 $e_i > e$ 时,$\mathbb{I}(e_i \leq e) = 0$
CDF曲线的解读规则:
坐标轴含义:
- 横轴:错误率阈值 (0-100%)
- 纵轴:CDF值,即错误率不超过阈值的概率 (0-1)
性能比较原则:
- CDF曲线位置越高,设计空间性能越好
- 曲线A在曲线B上方,说明设计空间A优于B
- 理想情况下CDF应快速上升并保持高值
网络采样与评估:
采样策略:
- 均匀分布采样:确保全面覆盖设计空间
- 早期停止训练:节省计算资源的同时保证评估有效性
- 小规模验证:在小型网络上验证设计原则
- 迁移验证:将发现的原则应用到大型网络
2.4 渐进式约束实验

NDS方法通过逐步引入参数约束,比较约束前后的CDF曲线变化来确定设计原则的重要性:
AnyNetXA → AnyNetXB:统一瓶颈比率
实验设计:
- 将4个阶段的瓶颈比率 $b$ 统一为相同值
- 从原有的独立设置改为全局共享
- 对比统一前后的CDF曲线性能
实验结果:
- 网络性能无显著变化
- 参数空间大幅简化
- 证明瓶颈比率可以全局统一
AnyNetXB → AnyNetXC:统一分组卷积组数
实验设计:
- 在瓶颈比率统一基础上,进一步统一分组卷积组数 $g$
- 4个阶段使用相同的分组数
- 继续观察CDF曲线变化
实验结果:
- 网络性能仍然保持稳定
- 设计空间进一步简化
- 验证了分组数统一的有效性
AnyNetXC:通道数变化模式比较
实验设计:
- 比较通道数的三种变化模式:递增、不变、递减
- 评估不同模式对网络性能的影响
- 确定最优的通道数变化策略
实验结果:
- 递增模式表现最佳 ($w_1 \leq w_2 \leq w_3 \leq w_4$)
- 不变和递减模式性能明显下降
- 渐进式通道扩展符合CNN特征提取规律
AnyNetXD:阶段深度变化模式
实验设计:
- 基于最佳通道数模式,比较阶段深度的变化模式
- 测试深度递增、不变、递减的效果
- 确定最优的深度分配策略
实验结果:
- 深度递增模式性能最佳 ($d_1 \leq d_2 \leq d_3 \leq d_4$)
- 后期阶段需要更多层来处理复杂特征
- 与通道数递增形成良好配合
2.5 CNN架构设计原则
基于实验得出的CNN网络架构设计重要原则:
参数统一原则:各阶段共享相同的瓶颈比率 $b$ 和分组卷积组数 $g$,简化设计空间而不损失性能
渐进扩展原则:通道数 $w_i$ 和阶段深度 $d_i$ 应随网络深入而递增,即 $w_1 \leq w_2 \leq w_3 \leq w_4$ 和 $d_1 \leq d_2 \leq d_3 \leq d_4$
简约优先原则:在保持性能的前提下,优先选择参数更少、结构更简单的设计
设计原则的理论基础:
这些原则反映了CNN特征提取的本质规律:
- 早期阶段处理低级特征,需要较少的计算资源
- 后期阶段处理高级抽象特征,需要更多的通道和层数
- 统一的超参数减少了设计复杂度,提高了可解释性
3. RegNet:规则化的网络设计
3.1 RegNet设计理念
RegNet的核心设计原则:
基于NDS方法得出的设计原则,RegNet采用规则化的网络架构:
全局统一:所有阶段共享相同的瓶颈比率 $b$ 和分组卷积组数 $g$
渐进增长:网络宽度(通道数)和深度(块数)随阶段递增
线性规律:通道数遵循线性增长模式
3.2 网络宽度的线性增长模型
理想的通道数增长模式:
RegNet假设理想的网络宽度应基于初始通道数 $w_0$ 随块索引 $j$ 以速率 $w_a$ 线性增加:
其中:
- $w_0$:初始通道数
- $w_a$:通道增长速率
- $j$:块的全局索引
线性增长的理论基础:
分段线性拟合:
- 由于同阶段内块共享通道数,线性变化实际上是分段的
- 需要在多个阶段中拟合线性关系
- 通过优化拟合误差确定最佳的阶段划分
优势:
- 提供了简单而有效的设计规则
- 减少了超参数搜索空间
- 便于不同规模网络的系统化设计
RegNetX系列网络:
RegNetX命名规则:
- RegNetX32:主体起始通道数为32
- RegNetX64:主体起始通道数为64
- 数字表示网络规模和复杂度
设计特点:
- 基于规则模式(regular patterns)的设计理念
- 通过继承AnyNet实现模块化构建
- 支持灵活的规模调整
RegNet vs 传统设计:
| 方面 | 传统手工设计 | NAS方法 | RegNet方法 |
|---|---|---|---|
| 设计复杂度 | 高 | 极高 | 中等 |
| 计算成本 | 低 | 极高 | 中等 |
| 通用性 | 低 | 低 | 高 |
| 可解释性 | 中等 | 低 | 高 |
| 设计洞察 | 有限 | 有限 | 丰富 |
RegNet在设计复杂度、计算成本和通用性之间实现了良好的平衡。
3.3 RegNetX32实现
RegNetX32网络配置:
RegNetX32作为RegNet系列的典型代表,通过继承AnyNet实现简洁的网络构建。
1 | class RegNetX32(AnyNet): |
查看RegNetX32模型结构分析
1 | if __name__ == "__main__": |
1 | =============================================================================================== |
3.4 RegNetX32参数分析
RegNetX32的具体配置参数:
基于NDS原则设计的RegNetX32具有以下参数配置:
- 茎输出通道数:$w_0 = 32$
- 瓶颈比率:$b = 1$ (无压缩)
- 分组卷积组数:$g = 16$
- 阶段深度:$d_1 = 4, d_2 = 6$ (递增)
- 阶段通道数:$w_1 = 32, w_2 = 80$ (递增)
模型效率分析:
- 总参数量:52,730 (约53K)
- 计算量:10.19 MMAC
- 内存占用:6.74 MB
- 参数效率:相比传统CNN大幅减少参数量
3.5 RegNetY:注意力增强版本
RegNetY的创新点:
RegNetY是RegNetX的扩展变体,在保持RegNet设计原则的基础上引入注意力机制:
SE模块集成:引入挤压-激励(Squeeze-and-Excitation)注意力模块
自适应加权:实现对各通道特征的自适应重要性加权
性能提升:在不显著增加计算成本的情况下提升模型性能
原则保持:CNN核心设计原则在RegNetY中依然适用
挤压-激励(SE)模块:
SE模块工作流程:
- Squeeze:全局平均池化压缩空间维度
- Excitation:两层全连接网络学习通道重要性
- Scale:将学习到的权重应用到原始特征图
数学表示:
其中 $\odot$ 表示逐元素乘法,$\sigma$ 为Sigmoid激活函数
RegNetX vs RegNetY性能对比:
| 指标 | RegNetX | RegNetY | 提升 |
|---|---|---|---|
| 参数量 | 基准 | +5~10% | 小幅增加 |
| 计算量 | 基准 | +2~5% | 微量增加 |
| 准确率 | 基准 | +1~3% | 显著提升 |
| 推理速度 | 基准 | -2~5% | 轻微下降 |
RegNetY在准确率和效率之间实现了良好的权衡,适合对精度有更高要求的应用场景。
RegNetX vs RegNetY选择指南:
选择RegNetX的情况:
- 计算资源极度受限
- 推理速度要求很高
- 参数量预算严格
- 边缘设备部署
选择RegNetY的情况:
- 对准确率有更高要求
- 计算资源相对充足
- 可以接受轻微的性能开销
- 服务器端或云端部署
4. 模型训练与性能评估
4.1 训练配置
实验设置:
继续使用training_tools.py中的工具对RegNetX32网络进行训练评估:
- 数据集:Fashion-MNIST (调整到96×96分辨率)
- 批次大小:128
- 训练轮数:10轮
- 学习率:0.05
- 优化器:SGD
1 | if __name__ == "__main__": |
4.2 训练结果分析
查看RegNetX32完整训练过程
1 | 第 001/10 轮,训练损失:0.9418,训练精度:66.48,测试损失:4.7452,测试精度:21.97 |
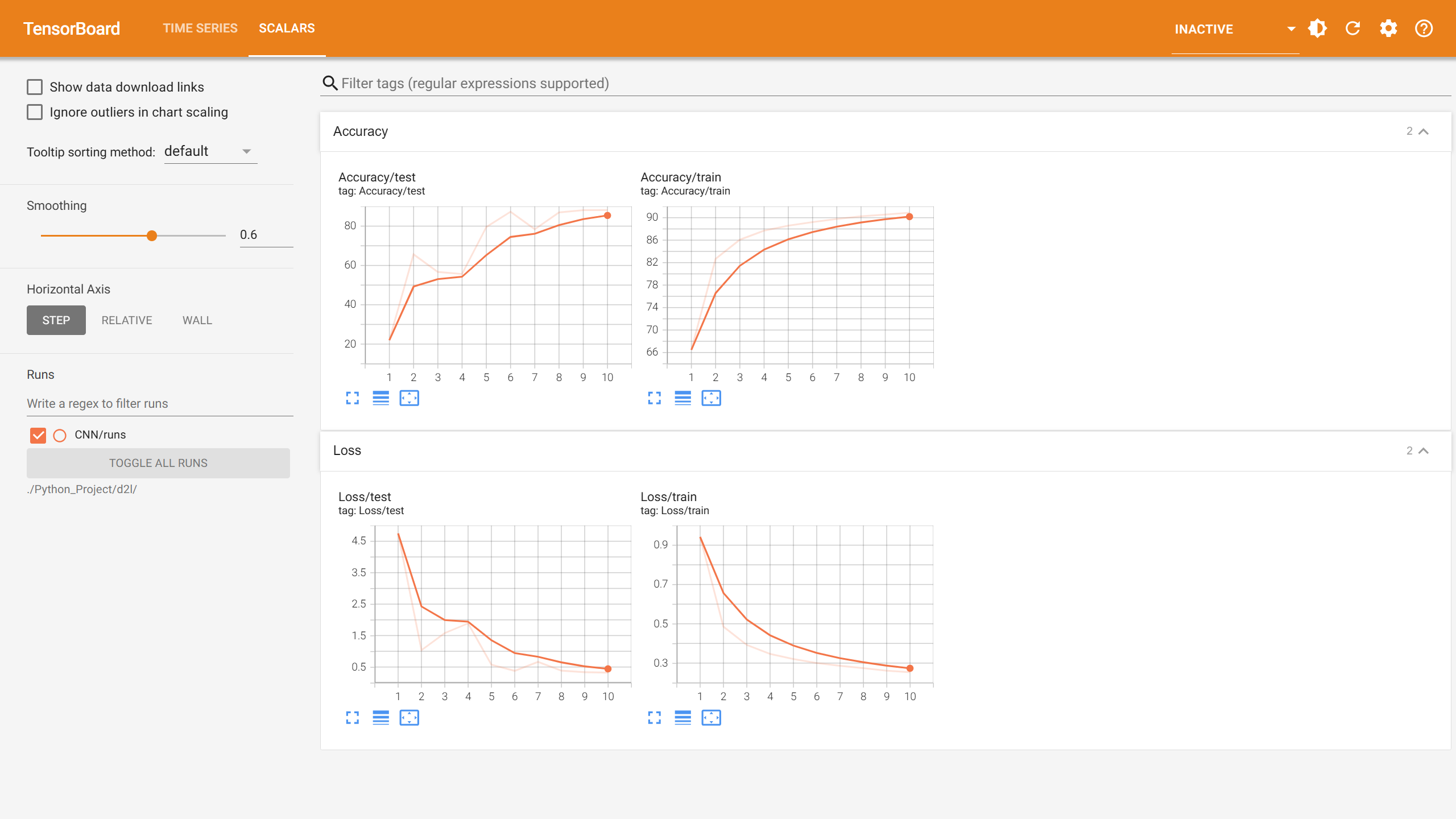
RegNetX32训练表现:
收敛性能:
- 最终训练精度:90.89%
- 最佳测试精度:88.16% (第10轮)
- 训练稳定性:相对稳定,波动较小
- 参数效率:仅53K参数实现良好性能
性能特点:
- 训练精度稳步提升,无明显过拟合
- 测试精度在中后期趋于稳定
- 损失函数收敛良好
- 体现了RegNet设计的有效性
与其他CNN架构的对比:
| 模型 | 参数量 | 最佳测试精度 | 训练稳定性 | 设计复杂度 |
|---|---|---|---|---|
| LeNet | ~60K | ~85% | 高 | 低 |
| AlexNet | ~60M | ~88% | 中 | 中 |
| VGG | ~138M | ~90% | 中 | 中 |
| ResNet | ~25M | ~93% | 高 | 高 |
| RegNetX32 | 53K | 88.16% | 高 | 中 |
RegNet优势:
- 极高的参数效率
- 基于系统化设计原则
- 训练稳定性好
- 易于扩展和调整
RegNet的应用价值:
适用场景:
- 移动端和边缘设备部署
- 参数预算严格的应用
- 需要快速原型设计的项目
- 教学和研究用途
技术优势:
- 系统化的设计方法论
- 可解释的设计原则
- 良好的性能-效率权衡
- 为未来架构设计提供指导
5. 总结与展望
5.1 CNN架构设计的发展历程
从手工设计到系统化方法的演进:
本文深入探讨了CNN网络架构设计从直觉驱动到系统化方法的重要转变:
手工设计时代:AlexNet、VGG、ResNet等经典架构的启发式设计
NAS技术:自动化搜索但计算成本极高
NDS方法:结合手工洞察与系统分析的高效解决方案
RegNet系列:基于设计原则的规则化网络架构
5.2 核心贡献与设计原则
NDS方法的重要发现:
- 参数统一原则:各阶段可共享瓶颈比率和分组卷积组数
- 渐进扩展原则:通道数和深度应随网络深入递增
- 简约优先原则:在保持性能前提下优选简单设计
- 可扩展性:设计原则在不同规模网络中普遍适用
5.3 技术影响与未来展望
CNN架构设计的未来趋势:
虽然Transformer架构在计算机视觉领域崭露头角,体现了”可扩展性胜过归纳偏置“的趋势,但CNN仍有重要价值:
- 资源受限场景:高效的CNN架构在边缘设备中不可替代
- 混合架构:结合CNN计算效率与Transformer表达能力
- 设计方法论:NDS方法为其他架构设计提供重要启发
- 理论指导:系统化设计原则推动架构设计科学化发展
对深度学习架构设计的启示:
RegNet的成功不仅在于具体的网络设计,更在于提供了一套系统化的架构设计方法论,为未来的网络架构创新指明了方向。
